

Web Crawlers
- Keet Malin Sugathadasa
- Jan 14, 2017
- 10 min read
This blog contains information related to web crawlers and how they work. Implementation of web crawlers will be in a separate article which will be published soon. Following are the main topics.
What is a Web Crawler?
Uses of a Web Crawler
How Do Web Crawlers Work?
The Architecture of a Web Crawler
Crawling Algorithms
Crawling Strategies
Crawling Policies
Example Web Crawlers
References
What is a Web Crawler?
A web crawler is a software bot (internet bot) that will surf through the world wide web in a systematic manner and collects required information in a meaningful way. Typically it's purpose is to do web indexing (web spidering).
Eg: Scooter (a crawler for the website and search engine named AltaVista)
Web indexing:
Web indexing refers to the various methods used to index contents and resources on the world wide web as a whole. Individual websites or intranets may use back-of-the-book index (internal indexing), while search engines use metadata (the information within the <head> tags of a html web page) and keywords to provide a more useful vocabulary for searching on internet.

Some web crawlers collect indexes of various resources and the collected information can be saved in a usable way. There are also some systems which use web crawlers to create a copy of all the visited pages, for later processing by a search engine, that will index the downloaded pages to provide faster searches.

Crawlers often consume a lot of resources on the systems they visit and most crawlers do visit these sites without a consent of the web page. Issues regarding to scheduling, load balancing and 'politeness' comes into play whenever web crawlers visit large collections of pages available online. Sometimes there are public websites that do not like web crawlers since they will consume a lot of resources and power of the servers being used by each of the web pages. For these reasons, including a robot.txt file ( also known as the robot exclusion standard ) can request the bots to index parts of a website, or nothing at all.
During the early days of internet, the web pages available on the world wide web were very large and even the largest crawlers built during those days were not accurate enough to make indices of those large pages. Therefore search engines were not very optimized those days, whereas nowadays that limitation has been eradicated by modern search engines, which manage to give very accurate results instantly.
Understanding about web crawlers is a very hard task. The pages available today in the internet is different from one another, which indirectly means that the web crawlers that we create should also be different from one another to suit specific tasks.
Uses of a Web Crawler
A web crawler is an automated script that can be used for various purposes and many websites and search engines do use a web crawler to ensure that they have the most reliable information at hand at all times. Following are some identified uses of a web crawler.
1) Search Engines
This is one of the main use cases that we use everyday on the internet, but we never really realize the inside story of how a search engine actually works. Just imagine surfing the internet without a search engine. It would be extremely hard and useless for a general user who wishes to find information required at that time. The accessibility of internet to everyone via search engines is actually provided with the help of indexing and other techniques where web crawling plays a vital role in the process. The following description actually shows how Google searching works and you will get a clear picture on the role of the web crawlers.
How Search Engines work?
Google has implemented millions of web crawlers in their systems to go through the world wide web and scrape down details, contents, links and many more into the internal servers of Google. This is a process done by Google so that they can store all the contents and score them and keep them in suitable manners, and results will be published instantly. Whenever we search for a word or phrase, Google does not actually run web crawlers at that very moment and gather required information, instead it will use the stored and scored contents and checks for a suitable keyword match in them.
To get a better understanding on how the process of automated web crawling happens in a search engine, consider a web crawler as a black box. And the input to this black box is a list of website links. At the beginning it has a small set of links that it already knows about and stores these as a URL list. Once this URL list is fed into the black box, it will extract keywords and links on each URL and whenever a new link is found, it will be fed back into the black box to extract the keywords and links. This process happens over and over again until some condition is met. Finally the black box will actually store a list of URLs along with the list of keywords in each of these URLs. Finally the stored content is being processed using a scoring mechanism, and talking about that will be way beyond our scope. If interested, visit this page.
It's more like a recursive process.

2) Automatic maintenance of website links
Web crawlers can also be used to carry out automatic maintenance tasks of web pages to keep the websites up to date. This can be used to update the web content on most of the pages so that the contents, links, validity of the code and other hyperlinks are always up to date, ensuring that there won't be any broken links for people who are browsing for information.

This research area is known as "Change detection in online resources." Some major components of this research is guided by web crawlers whereas the focus is on automatically identifying intentional and unintentional modification of web contents and updating relevant references for that particular content or resource. And web crawlers play a major role in checking for the validity of the contents on each of the web pages of interest.
Crawlers can validate hyperlinks and HTML code. They can also be used for web scraping.
3) Data Scraping
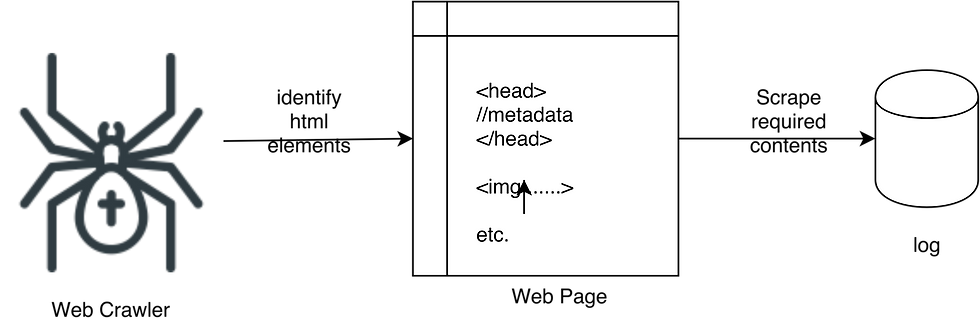
Data scraping is the technique in which a computer program or a bot, extracts data from human readable output coming from another program. This is something that developers love. Web crawlers can be used to scrape data, contents and information from a specific website. When developing a web crawler for this purpose, it is easy if we are developing one for a selected web page, because we can tell what kind of information should be extracted and how to do so. This task becomes extremely tough when information needs to scraped from many different web pages whereas the web crawler needs be more generalized to suit our requirement. Following are some identified easy steps for you to build a simple web crawler.
Identify the html elements (html tags) that contain the information you want.
Construct a web crawler app that will scrape those elements
Run the web crawler and generate a log file containing those data. (May be save to a database)
How Do Web Crawlers Work?
Web crawlers will start with a set of URLs at the beginning, and these URLs are called "Seeds". When the crawler visits these URL's one by one, it will read the contents in those URL's and collect the hyperlinks and will add them to the list of URLs to be visited, and this list is called the "Crawl Frontier". These URLs will be visited by the crawler in a recursive manner according to a set of policies and crawling strategies, whereas, if archiving of websites is needed by the system, it will ensure to save all the visited webpages.
In the process of web crawling, it will face a lot of issues like, large websites, inefficiency, bandwidth and duplicate contents. So at each URL scan, the crawler must carefully choose which pages to visit next.
The Architecture of a Web Crawler
The abstract architecture of a web crawler can be defined in many ways and a diagram is shown below. The quality and features of each architecture, depends on the "crawling strategy" being used (mentioned below) and the "crawling policies" being used (mentioned below).

A more complex and detailed architecture diagram of a web crawler is given below. Details on each component is explained below the diagram.
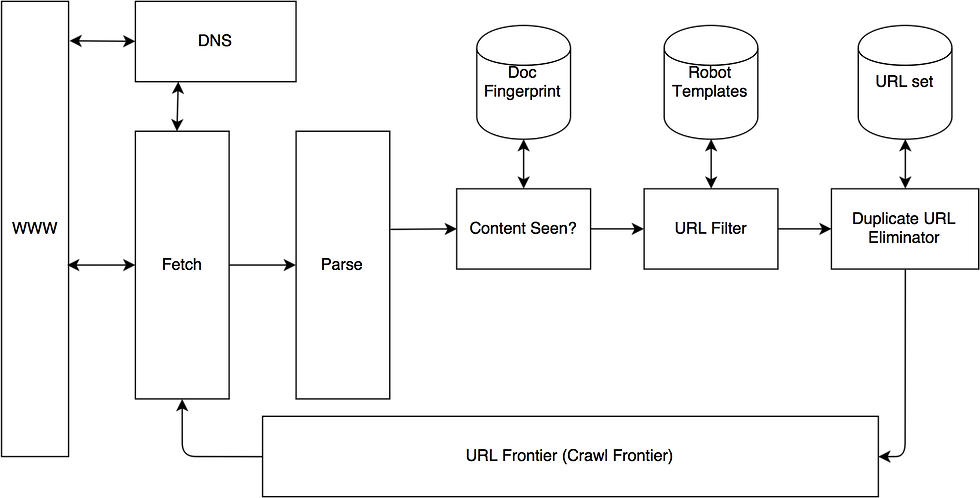
WWW - World Wide Web
DNS - Domain Name Service. Look up IP addresses for each domain name
Fetch - Generally uses the HTTP protocol to fetch URL
Parse - The retrieved page is parsed. Texts, videos, images and links are extracted
Content Seen? - Test whether a web page with the same content has already been found in another URL. Need to develop a way to measure the fingerprint of a web page
URL Filter - Whether the extracted URL should be excluded from the crawl frontier (robot.txt). The URLs also should be normalized.
Duplicate URL Elimination - The URL is checked for duplication elimination
URL Frontier - Contains URLs to be fetched from the current crawl. At first a seed set is stored in the crawl frontier.
Crawling Algorithm
Following pseudo code represents the basic flow of how a web crawler works. We can see different implementations being used in many places. But this will let you get a general idea on how it actually works in terms of implementation.
Initialize queue (Q) with a known set of URLs (seed URLs)
Loop until Q is empty, or a certain condition is met
Pop/Dequeue (Depends on the implementation technique being used) URL (L) from Q
If L is not an HTML page (.gif, .jpeg, etc) then exit loop
If L is already visited, continue loop (get net URL)
Download page (P) for L
If cannot download P (404 error, robot.txt included in L), exit loop
Else,
Index P (add to inverted index or store cached copy)
Parse P to obtain a list of new links (N)
Append N to the end of Q

Crawling Strategies
The World Wide Web is a huge cob web and the spider is supposed to do all the crawling around to go to the required places. In technical terms, the WWW (World Wide Web) is a huge directed graph with resources as vertices and hyperlinks as edges. Therefore it is needed to use a suitable graph traversing algorithm to find whatever you need. Following are two widely used traversal algorithms for web crawling.
More careful by checking all alternatives
Complete and optimal
Very memory intensive
Neither complete nor optimal
Uses much less space than Breadth-First
Crawling Policies
The behaviour of a web crawler is defined by the following policies, which could be a combination of the following four policies.

1) Selection Policy (which pages to download)
Restricting followed links
Purpose: To seek out HTML pages only and avoid all other MIME types.
Eg:
Make an HTTP HEAD request to determine a web resources MIME (Multipurpose Internet Mail Extensions) type before downloading the entire website.
Avoid requesting any resources that have a "?" in them. These are dynamically produced and would lead to "spider traps" causing the crawler to download an infinite number of URLs from a website.
URL normalization
Purpose: To avoid crawling the same resource more than once
Eg:
Conversion of URLs to lowercase, removal of "." and ".." segments, and adding trailing slashes to the non-empty path component.
Path-ascending crawling
Purpose: To download as many resource as possible from a particular website
Eg:
If the URL is "http://keetmalin.wix.com/keetmalin/blog/single-post", it will attempt to crawl "/keetmalin/blog/single-post", "/keetmalin/blog", "/keetmalin", "/".
Focused crawling
Purpose: Attempt to download pages that are similar to each other. (focused segment)
Eg:
Crawl for web resources related to a focus area like "food".
Academic focused crawling
Purpose: To crawl for free access academic related documents
Eg:
2) Re-visit Policy (when to check for changes to the pages)
The World Wide Web is changing everyday. Due to its dynamic dynamic environment crawling a fraction of the web may take weeks or even months. if it takes a longer time to retrieve the content, the web may have gotten updated by the time the retrieval is complete.
Cost factors play an important role when it comes web crawling. The most common cost functions are "Freshness" and "Age". The final objective of the crawler in terms of cost functions is to get a high average of freshness and low average age of web pages. The diagram below shows the evolution of Freshness and Age of a web crawler.
When a web page is synced, the freshness of the page goes high (since the updated content is fresh), and the age of the page goes down (Since the newly updated page is young). But when a web page is modified, the freshness goes down, because the web page we have saved is out dated. And when it is modified, the currently saved webpage we have starts to out date and due to that reason, the age goes up (old).

There are two commonly used revisit policies.
Uniform policy: This involves re-visiting all pages in the collection with the same frequency, regardless of their rates of change
Proportional policy: This involves re-visiting more often the pages that change more frequently. The visiting frequency is directly proportional to the (estimated) change frequency
3) Politeness Policy (how to avoid overloading of websites)
Even though crawlers can do searching and retrieving content in a much faster and more accurate ways than humans, they tend to make some impolite effects on the website, by consuming more bandwidth and power. Due to these reasons, the websites tend to block web crawlers by using robot.txt protocol (robot exclusion protocol) in each of the web pages.
In terms of politeness, following are the identified cost functions
Network Resources - bandwidth
Server Overload - frequency of accesses
Server/ router crashes - download pages where the crawler cannot handle
Network and server disruption - if deployed by too many users
4) Parallelization Policy (how to coordinate with distributed web crawlers)
A parallel crawler is a crawler where multiple processes are run in parallel. There are three identified goals to use this policy
To maximize the download rate
To minimize the overhead from parallelization
To avoid repeated downloads of the same page
Example Web Crawlers
Yahoo Slurp - Yahoo search crawler
Msnbot - Microsoft's Bing web crawler
Googlebot - Google's web crawler
World Wide Web Worm - Used to build a simple index of document titles and URLs
Web Fountain - Distributed, modular crawler written in C++
Slug - Semantic web crawler
References



Comments